AI systems are becoming limited by heat as much as by compute and memory bandwidth. Modern accelerators use 2.5D and 3D integration to bring GPUs, chiplets, and HBM closer together. This improves bandwidth and integration density, but it also increases heat flux and makes cooling more difficult [1].
Temperature directly affects performance. GPUs reduce frequency when they exceed thermal limits. HBM increases refresh rate at higher temperatures, reducing effective bandwidth and increasing latency. As a result, the real performance of an AI package depends on the interaction between workload, power, package design, cooling, and throttling [1].
This makes thermal-aware system-technology co-optimization necessary. Package choices need to be evaluated based on sustained workload performance, not just peak bandwidth or ideal compute capability.
UCLA’s Thermal-Aware Simulation Framework
Prof. Puneet Gupta’s group at UCLA developed a simulation framework to address these challenges. The UCLA team built a closed-loop methodology that connects AI workload behavior, chiplet power, package temperature, and temperature-driven throttling [1].
The framework helps answer practical design questions early in the architecture and packaging process. How much benefit does 3D stacking really provide after thermal throttling? Which material changes improve performance? Does stacking order matter? How much performance can be recovered with better cooling?
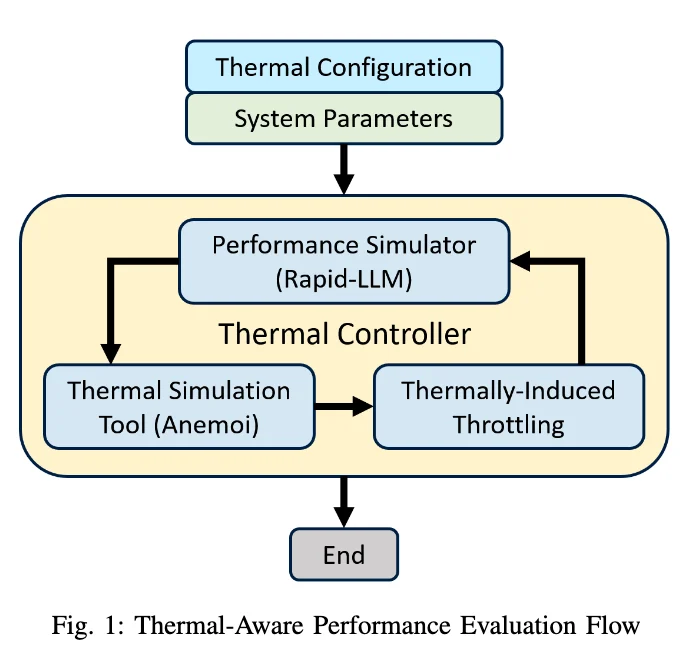
By connecting workload simulation with package-level thermal modeling, the UCLA framework evaluates package and cooling decisions in terms of end-to-end LLM training and inference runtime.
Main Highlights
3D integration can improve ideal performance by increasing GPU-to-HBM bandwidth, but it also creates a more difficult thermal path. In the evaluated systems, 3D configurations showed a larger performance penalty from throttling than comparable 2.5D configurations [1].
Material choices matter only when they affect the dominant heat path. Improving the thermal interface material produced a meaningful performance benefit, while improving underfill and infill had little impact in the studied stackup [1].
Cooling had the largest system-level effect. A stronger cooling solution recovered significant performance and nearly eliminated throttling in some 3D cases. This shows that cooling must be considered part of the system architecture, not a late-stage mechanical detail [1].
The study also shows that 3D stack order matters. Placing compute closer to the heat spreader improves sustained performance because the GPU has a better thermal path. Taller HBM stacks increase thermal pressure, making future high-capacity memory systems more dependent on thermal-aware design [1].
Anemoi Software's API-Based Thermal Analysis
The framework uses an API-based thermal simulation flow built around Anemoi Software’s thermal engine [2]. The workload simulator estimates GPU and HBM utilization and converts that activity into chiplet power. Those power values are passed to Anemoi to evaluate the package stackup, material properties, chiplet placement, and cooling boundary conditions [1].
Anemoi returns peak GPU and HBM temperatures. These temperatures are used to update the performance model by applying GPU DVFS and HBM refresh throttling. The loop repeats until the system reaches a consistent thermal and performance state.
This turns thermal simulation into part of architecture exploration. Package options such as 2.5D versus 3D, TIM selection, HBM stack height, stacking order, and cooling strength can be compared by their impact on actual AI workload performance.
Conclusion
AI accelerators will deliver their full value only when package architecture, materials, cooling, and workload behavior are optimized together. Higher bandwidth, denser integration, and taller memory stacks are useful only if the system can sustain performance without excessive GPU and HBM throttling.
Prof. Gupta’s UCLA team demonstrates how to evaluate that tradeoff with a workload-aware STCO framework connected to Anemoi’s thermal simulation capability. As AI packages move toward denser chiplet integration and more aggressive 3D stacking, thermal-performance closure becomes a requirement for system design.
The architectures that matter will be the ones that sustain performance under real thermal constraints, not simply the ones with the highest theoretical bandwidth or compute density.
References
[1] D. Ray, G. Karfakis, A. Graening, D. Ratchkov, and P. Gupta, “Thermally-Aware System-Technology Co-Optimization for AI Systems,” UCLA NanoCAD Lab. Available: https://nanocad.ee.ucla.edu/wp-content/papercite-data/pdf/c137.pdf
[2] Anemoi Software, https://anemoisoftware.com